


# 超有趣!自制 WordPress 采集插件教程来袭
## 写在前面
一直以来,写代码我常用 C++ 和 Python,PHP 只是多年前做博客时玩过几天。最近换工作等离职,实在无聊,就做了个插件玩玩。要是用着觉得不好,欢迎提建议,我一定认真采纳,努力把插件优化得更好。
开发时,我尽量让配置简单易懂,但为了保证插件灵活性,还是得了解点正则和 xpath 规则。懂这些的话,这教程超简单,一看就会;要是没接触过也别怕,看例子照抄就行。毕竟是首个版本,有些地方可能写得不够详细,欢迎大家指出。
## 下载和安装
1. 打开 [https://crawling.cn](https://crawling.cn) 下载最新版,得到 crawling_v*.tar.gz。
2. 解压压缩包,上传到 WordPress 插件目录,激活插件。
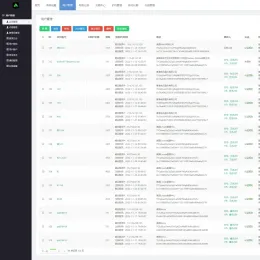
## 任务管理
一个任务就像一个爬虫,能配置多个任务,每个任务都能单独设参数。比如我设置了三个任务:
- 任务一:爬取“且听风吟”(我超爱的电影网站)全部内容,抓取间隔设为 -1,只采集一次。
- 任务二:爬取“且听风吟”前三页,已采集的不重复,只抓更新内容,每隔 24 小时采集一次。
- 任务三:爬取“阳光电影网”(电影天堂新网站)首页全部更新电影,每 24 小时采集一次。
每个任务设置如下:
1. **任务名称**:任务别名,方便记忆。
2. **入口网址**:爬虫起始地址,一般是首页或列表页。
3. **爬取间隔时间**:任务运行间隔。
4. **列表页面 url 正则/内容页面 url 正则**:爬虫进入入口网址后,需区分内容页面和翻页,所以要设这两个正则表达式。可在《正则表达式在线测试》页面测试。
5. **文章标题(xpath)/文章内容(xpath)**:进入内容页面后,用 xpath 告诉爬虫抓取内容。配置后可在《XPath 在线测试》页面测试。
6. **内容起始字符串/内容结束字符串**:过滤广告等无用内容,可通过设置字符串实现。
7. **文章图片**:可选择保存到本地或不处理。
8. **文章分类**:可选择多个分类。
9. **文章标签**:单独设置,多个标签用 | 分隔。
10. **发布方式**:可选择“立即发布”或“放入草稿箱”。
## 高级选项
1. **爬取线程数**:根据主机配置设置,独立主机可多线程,虚拟主机别设太大。
2. **抓取延时**:防止采集过快,避免被封站。
## 最后
配置好就等插件执行,想终止可在“任务管理”页面顶部切换运行状态。
本站文章原创,未经同意禁止复制盗用。若侵犯权益,可联系处理。
#php #WordPress #采集教程
解压密码: 7 天内有效




暂无评论内容